
Mało osób zdaje sobie sprawę z istnienia pliku „robots.txt”, a jeszcze mniej wie, jakie ma on przeznaczenie. Tymczasem ten prosty tekstowy plik może mieć bardzo duży wpływ na indeksowanie całej witryny. Za pomocą kilku komend możemy sterować robotami wyszukiwarek, które docierają na stronę w celu jej indeksowania w wynikach wyszukiwań. Czym dokładnie jest robots.txt i jak można go stworzyć, jeśli nie znajduje się na serwerze?
Co to jest robots.txt?
Plik robots.txt pełni rolę pośrednika pomiędzy witryną internetową a robotami wyszukiwarek. Dzięki niemu roboty mogą komunikować się z daną stroną. W niniejszym pliku zastosowane są odpowiednie komendy zgodne ze standardem Robots Exclusion Protocol. Jest to kombinacja komend, zapisana w języku zrozumiałym dla robotów wyszukiwarek. Plik robots.txt znajduje się w katalogu głównym domeny.
Specjaliści często wykorzystują i uwzględniają omawiany plik w audycie SEO, by mieć lepszy obraz aktualnego stanu witryny.
Wykorzystując mechanizm Robots Exclusion Protocol możemy przekazywać automatom informacje o tym, jakich działań nie powinny podejmować na stronie WWW. Domyślnie boty indeksują całe serwisy internetowe, podążając za kolejnymi linkami. Wtedy w wyszukiwarce mogą się znaleźć również podstrony, których autor danej witryny nie chce indeksować, ponieważ jest to zbędne. Niektórzy autorzy wcale nie chcą indeksować swoich stron w wyszukiwarkach i wolą, aby pozostałe one anonimowe. Wtedy również przydają się możliwości pliku robots.txt.
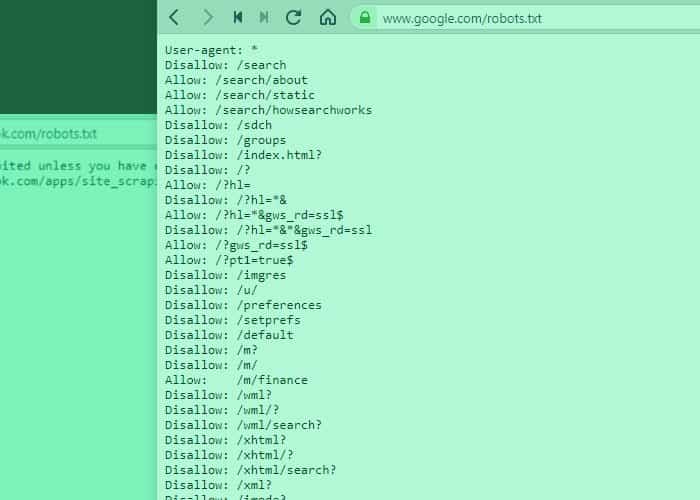
Należy pamiętać o tym, że komendy znajdujące się w pliku robots.txt pełnią jedynie funkcję informacyjną i nie wymuszają żadnych działań. Roboty najpopularniejszych wyszukiwarek zwykle przestrzegają zasad zawartych w pliku, jednak niektóre roboty mogą je zignorować, szczególnie te złośliwe.
Jak stworzyć plik robots.txt?
Plik robots.txt można stworzyć w najprostszym edytorze tekstowym, przykładowo może to być notatnik w systemie operacyjnym Windows. Oczywiście plik koniecznie musi nazywać się „robots.txt”, a każda witryna może posiadać tylko jeden taki plik. Tak przygotowany plik trzeba jeszcze wgrać na serwer, korzystając z klienta FTP takiego jak Filezilla czy Total Commander. Plik oczywiście wgrywamy do głównego katalogu domeny. Z poziomu klienta FTP możemy dowolnie edytować plik, a zmiany będą natychmiast zapisywane na serwerze.
Trzy podstawowe polecenia, za pomocą których można wprowadzać zmiany w pliku robots.txt to:
- User-agent – określa nazwę identyfikacyjną bota wyszukiwarki, może to być np. Google, Yahoo czy DuckDuckGo. Polecenie może zostać wykorzystane, aby definiować reguły dla robotów poszczególnych wyszukiwarek.
- Disallow – jest to polecenie, które informuje roboty wyszukiwarek, jakiego obszaru strony WWW nie powinny indeksować.
- Allow – polecenie, które przydaje się, gdy pewien folder, który chcemy indeksować, znajduje się wewnątrz folderu oznaczonego komendą „disallow”. Dzięki temu poleceniu możemy zezwolić na indeksowanie pewnego obszaru wcześniej wykluczonego folderu.
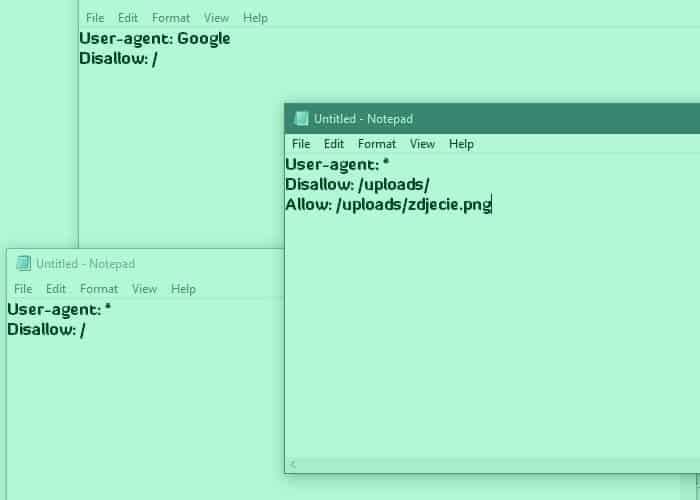
Najprostszym przykładem pliku robots.txt może być zablokowanie robotów wyszukiwarki Google przed dostępem do witryny. Wówczas powinniśmy użyć poniższych poleceń:
User-agent: Google
Disallow: /Jednak jeśli będziemy chcieli, aby witryna pozostała anonimowa i nie pojawiała się w żadnych wyszukiwarkach, wystarczy, że zmienimy polecenie User-agent i zamiast „Google”, dodamy „*” – gwiazdkę.
User-agent: *
Disallow: /Inny przykład to wykorzystanie polecenia „allow”, a więc gdy chcemy dać robotom dostęp do pewnej części folderu (w tym przypadku zdjęcia), który znajduje się pod poleceniem „disallow”.
User-agent: *
Disallow: /uploads/
Allow: /uploads/zdjecie.pngOczywiście to tylko przykładowe kombinacje najprostszych komend. Wszystko zależy od tego, jakie efekty chce osiągnąć dany użytkownik i jakie obszary swojej witryny chce zablokować przed indeksowaniem. Poprawność stworzonego pliku robots.txt można sprawdzić w testerze Google Search Console. Aby to zrobić, wystarczy wpisać w wyszukiwarce „tester pliku robots.txt” i wybrać pierwszą pozycję supportu Google. Następnie należy podążać za kolejnymi punktami. Testowanie pliku jest istotne, jeśli tworzy go osoba bez doświadczenia. Pozwoli to uniknąć ewentualnych błędów, które mogą negatywnie wpływać na indeksowanie strony.
Czy robots.txt jest wymagany?
Plik robots.txt nie jest wymagany. Plik jest pomocny głównie wtedy, gdy chcemy ukryć jakiś obszar witryny przed robotami wyszukiwarek. Wtedy korzystając z odpowiednich poleceń, możemy sterować botami wchodzącymi na naszą stronę WWW. Jednak jeśli chcemy, aby cała witryna była indeksowana, to plik robots.txt jest zwyczajnie zbędny. Niektóre osoby umieszczają na serwerze nawet pusty plik robots, jednak to również całkowicie zbędne działanie. Co więcej, według najnowszych informacji Google przestaje zwracać uwagę na zawartość pliku robots. Ponadto warto pamiętać o tym, że wyszukiwarka Google może indeksować adresy URL, które pojawiły się na innych stronach w sieci. Jeśli ktoś udostępnił adres naszej strony w Internecie, to wyszukiwarka może zdobyć powszechnie dostępne informacje do tych treści i będzie wyświetlać je w wynikach wyszukiwania. Stanie się tak nawet, jeśli dane adresy będą zablokowane w pliku robots.txt.


